
在 AI 技術高速發展的今天,「讓機器真正理解世界」的需求從未如此迫切。無論是電商平臺的跨模態搜索、智能助手的多輪對話,還是內容平臺的精準推薦,底層都依賴一個關鍵能力——將文本、圖像、視頻等不同形態的信息,轉化為計算機可理解的「向量」,并通過向量間的關聯實現高效匹配與檢索。
6月24日,火山引擎發布全模態向量化模型 Seed1.6-Embedding,通過三大核心突破,重塑向量化能力邊界:不僅在權威測評榜單中包攬中文文本、多模態全面任務的 SOTA 成績,更首次實現「文本+圖像+視頻」混合模態的融合檢索,并通過自定義指令能力大幅降低業務落地門檻。
從“單模態支持”到“全任務領先”:Seed1.6-Embedding的技術實力
針對行業對多模態深度理解和高效檢索的雙重需求,團隊采用文本繼續訓練-多模態繼續訓練-精調的多階段訓練策略,基于海量文本、圖文對、視頻文對數據,構建多任務數據集,通過指令引導、數據合成、數據增強、分層負樣本等混合訓練,提升細分場景和復雜任務處理能力,讓其成為覆蓋全場景的向量化“全能選手”。
全面任務領先:包攬中文文本、圖像、視頻「三冠」
在最能體現模型泛化能力的權威榜單中,Seed1.6-Embedding 均展現出顯著優勢:
純文本任務:在 CMTEB 中文文本向量評測榜單上,模型以75.62高分刷新榜單 SOTA,在檢索、分類、語義匹配等通用任務表現持續領跑;

多模態任務:在多模態評測榜單 MMEB_v2中,模型的圖片、視頻向量化任務雙雙登頂 SOTA,并實現斷層領先。其中在 MMEB_v2 Image 榜單上,模型以77.78的高分領先第二名5.6分;模型新增的視頻模態,在 MMEB_v2 video 榜單大幅領先第二名20.1分。
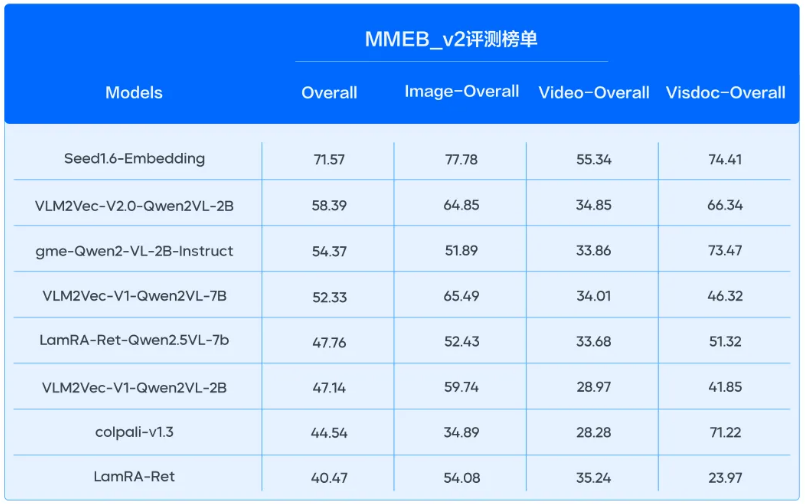
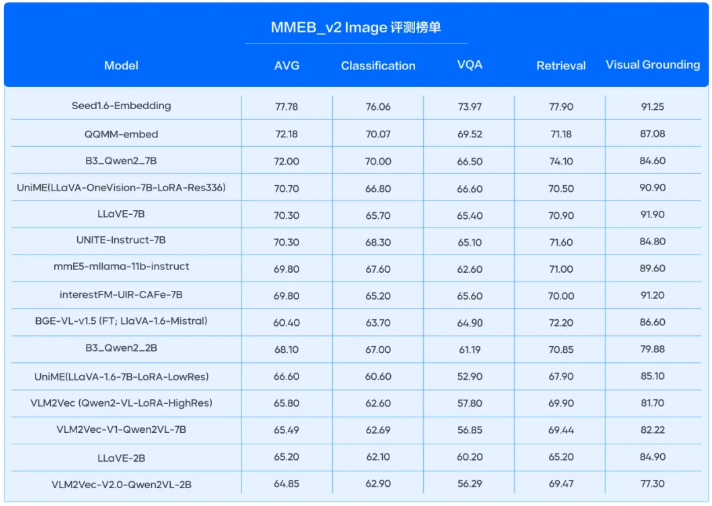
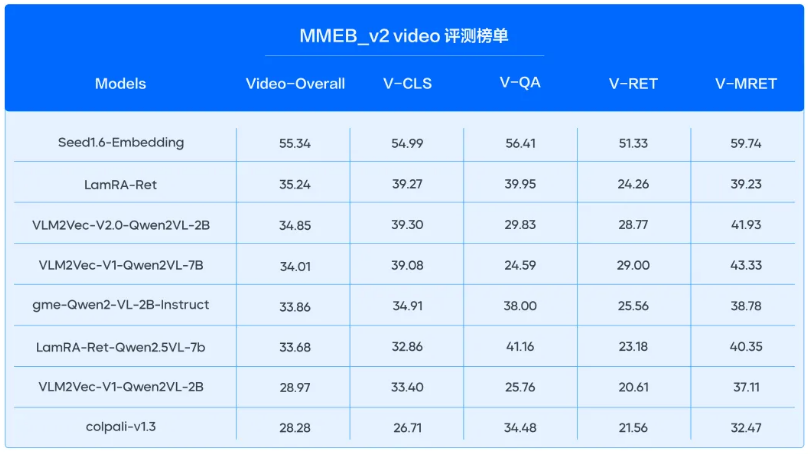

全模態混合檢索:支持“文+圖+視頻”統一向量空間表征
過去,多模態向量化模型往往局限于單模態輸入-單模態輸出的模式,而真實場景中,用戶需求通常是通過混合搜索如文搜圖和視頻、文圖搜視頻等方式來精準檢索目標內容。Seed1.6-Embedding 突破單一搜索限制:
新增視頻向量化能力:支持對人物、動作、場景等視頻核心語義的統一表征;
全模態混合檢索:支持文本、圖像、視頻等多形態輸入的混合表征,輸出的向量能同時保留不同模態的關鍵特征,真正實現「跨模態搜索無界」。
自定義指令增強:讓向量生成“按需而變”
業務落地中,不同場景對向量的關注點往往不同:電商需要突出商品的價格、材質等,新聞平臺需要強調事件時間、情感傾向。過去,企業常需投入大量標注數據微調模型,成本高、周期長。
Seed1.6-Embedding 通過指令增強技術,讓向量生成更“聽話”:用戶只需通過定制化指令模板,就能像給模型下任務清單一樣,精準引導向量生成更貼合業務目標的表達。這一能力讓模型適配新場景從“重訓練”變為“輕調整”,低成本支持電商精準推薦、知識問答等多樣化需求,實現一模型多場景,靈活隨需而變。
從“技術突破”到“場景落地”:火山方舟讓能力「觸手可得」
好的模型,最終要服務于真實場景。為了讓 Seed1.6-Embedding 更快、更省心地服務于實際業務需求,火山方舟同步推出兩大支持入口:
火山方舟 API 接口:模型已上線火山方舟控制臺,專業開發者可直接調用 API,無需自建模型訓練與部署環境,即可快速接入業務場景;
VikingDB 向量數據庫:火山方舟旗下 VikingDB 向量數據庫已深度集成 Seed1.6-Embedding模型,提供“向量生成+存儲+檢索”的一站式解決方案,企業無需額外開發,開箱即用。
未來,團隊將繼續深耕向量化技術。預計2025年下半年,用戶可在火山方舟體驗中心實現可視化體驗和多模態檢索,VikingDB 向量數據庫也將支持全模態數據自動向量化,并開放圖文和視頻檢索開源項目,助力企業和開發者快速集成到業務場景。火山引擎也將以更開放的姿態,攜手企業與開發者,共同探索 “讓 AI 理解世界” 的更多可能。
免責聲明:市場有風險,選擇需謹慎!此文僅供參考,不作買賣依據。






